Anomaly Detection and Diagnosis from System Logs through Deep Learning
Abstract
- Log는 시스템의 상태와 주요 events를 리코드
- 연구는 LSTM을 활용해 시스템로그를 분석함. 자동적으로 normal execution과 anomaly를 찾는다
- 시스템이 deploy된 이후에도 모델의 업데이트를 계속 진행. Online 상태에서 데이터를 지속 수집하여 분석한다
- PCA, SOM같은 전통적인 데이터마이닝 방식보다 DNN을 활용한 방식의 성능이 좋았음
1. Intoriduction
- System 보안에 있어서 anomaly detection은 중요한 문제
-
Log Data는 비정형. 실시간으로 데이터를 분석해 anomaly를 밝히는 것은 더 어려운 task. Decision이 data가 Streaming되는동안 이루어져야만 한다
Contribution
- RNN(LSTM)을 활용해 sequential한 log data를 실시간 anomaly detection
- Log data의 key뿐만 아니라 함께 들어온 다양한 values를 분석에 사용(즉, multivariate analysis)
- It is able to capture different types of anomalies
- 적은 양의 정상데이터로 학습
- HDFS log dataset의 1%만을 학습하여 나머지 99%의 데이터에대해 거의 100%의 detection accuracy를 냄
- 잘못 분류된 anomaly는 유저의 평가를 통해 모델에 학습됨
2. Preliminaries
2.1 Log Parser

- Log(특히 IoT기기에서 출력하는) data는 Semi-Structured. 이것을 Structured하게 representation.
- entry $e$ = “Took 10 seconds to build instance.” 에 대해서 key $k$ = Took * seconds to build instance.이고 asterisk가 parameter이다. 학습데이터 HDFS는 여러개의 parameter를 가짐
- 과거의 로그분석은 timestamp와 parameters를 버리곤 했지만 여기서는 모두 활용
- DeepLog에서는 경과시간(time elapesd)을 key, parameter와 함께 활용 (아마 기존 분석이 로그의 순서만을 이용했다면 여기서는 순서+로그사이 경과시간까지 고려하겼다는 얘기로 보입니다)
2.2 DeepLog Architecture and Overview
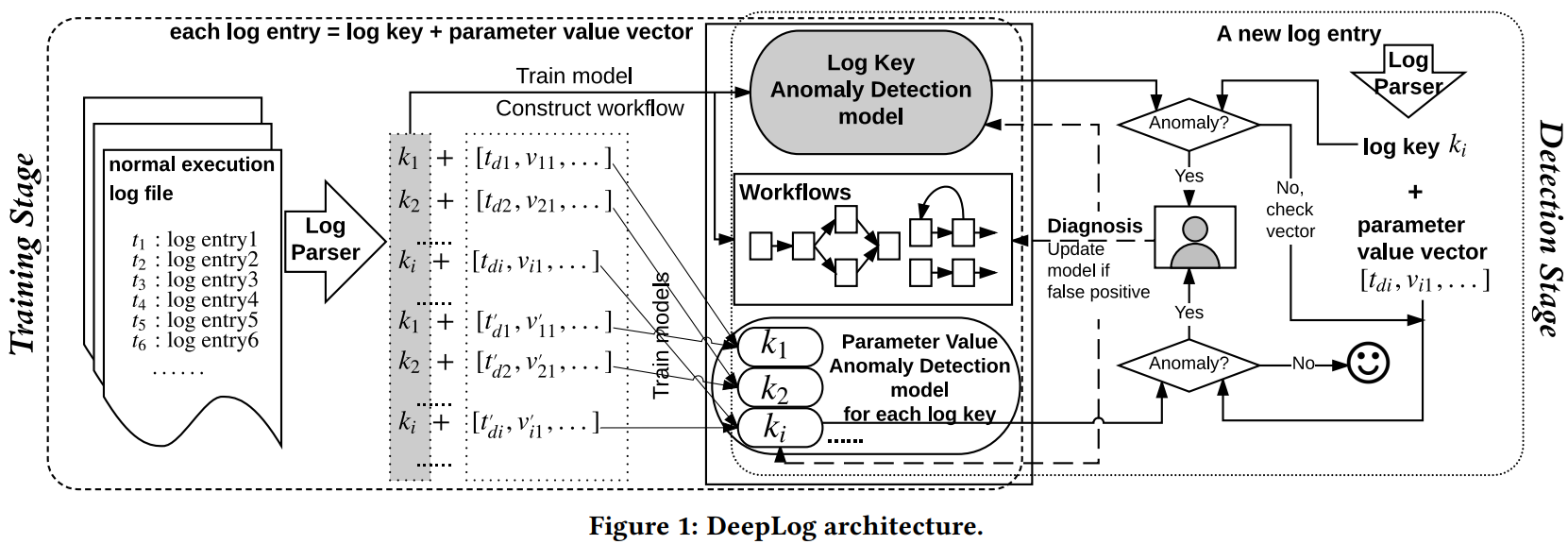
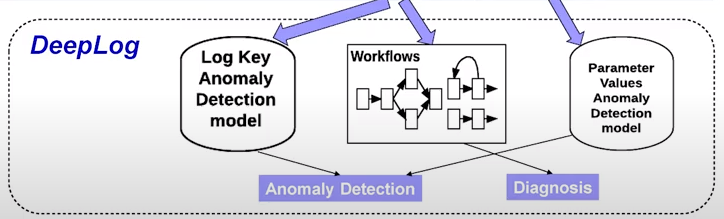
A. Training Stage
- 정상 $e$가 입력되어 $k$와 parameter value vector로 나뉨.
B. Detection Stage
- $e$가 입력되어 $k$와 parameter value vector로 나뉨. $k$가 비정상인지 판단 후 비정상이라면 유저에게 알리고 정상이라 판단되면 parameters에 대해 비정상인지 판단함. 둘 중 하나라도 비정상이라고 판단되면 비정상이라고 결론내림. 유저가 개입하여 1종오류를 모델에 알릴 수 있음
3. Anomaly Detection
- window size $h$로 슬라이싱하며 입력. Classification 문제로 생각한다. $Pr[m_{t} = k_{i}\mid w]$. 여기서 $w$는 연속된 key가 있는 벡터
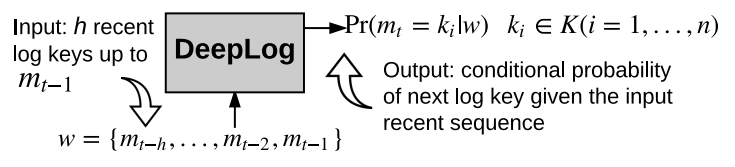
$$Pr(m_{t}=k_{i}\mid m_{1},...,m_{t-1})=Pr(m_{t}=k_{i}\mid m_{t-N},...,m_{t-1})$$
- $h$ 이전의 사건은 현재의 사건에 영향을 미치지 않는다고 가정한다. 마치 N-gram 언어모델같다
- encode-decode형식을 사용한다. $k_i$는 one-hot 벡터로 입력
- parameter value 예측에도 비슷한 LSTM구조가 쓰였으며 value들은 regression 문제로 보았다
- $g$ : DeepLog모델은 input에 대해 key 개수 만큼의 확률을 출력할 것이다. 소프트맥스 확률을 sort해서 $g$개까지 뽑는다. 다음에 입력된 input이 이 candidates $g$사이에 있다면 normal한 flow로 판단한다. 만약 $g$개 candidates사이에 다음 입력된 key가 없다면 anomaly로 모델은 판단한다. 그 후의 일은 4. Workflow 에서 다루겠다
- $g$는 hyper-parameter
- 다음에 입력될 key의 sequence에 대해서는 학습할 수 있지만 이것이 정상 flow인지 아닌지는 위와같은 방법으로 비지도학습
4. Workflow Construction
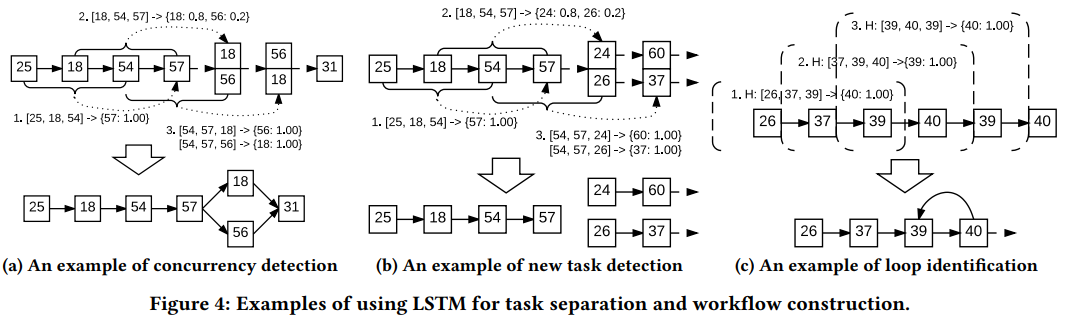
- 특이하게 heuristic한 방법을 활용한다. 반복된 패턴을 workflow로 저장한다. 학습에서 confidence=1 또는 분기에 있는 key들의 확률 합이 1인 경우에만 workflow로 지정한다고 한다. 이때 3가지 유형을 기억하는데 (a) 동시실행(분기) (b) 완전분기 (c)사이클 의 경우이다.
- 이런 workflow로 지정되는 key들은 각각의 등장확률의 합이 1이되는 경우만 해당되는 것으로 보인다. (i.e. 18→54→57 후 18또는 56이 나올 확률을 더하면 1이 되는 확실한 상황에만 workflow로 지정. workflow가 틀릴 수도 있다. 사용자 feedback으로 수정해나감)
- User는 workflow를 통해서 False Positive가 생긴 경우에 원인 진단에 사용할 수 있다고 한다. 관리자의 피드백을 바로 워크플로우에 추가하거나 lstm 모델을 업데이트 하는데 쓸 수 있다. 이는 online learning에서 새로운 유형의 anomaly가 등장했을 때 정말 이것이 이상치인지 맞다면 유저의 판단하에 모델이 학습할 수 있게 한다
5. Evaluation
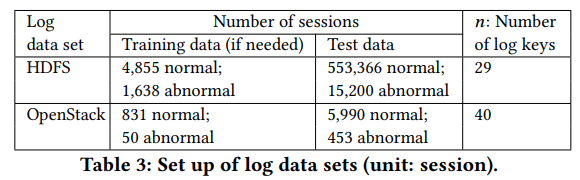
- 다음 key를 예측하는 task. $h$ = 10, $\alpha$ = 64(LSTM gate 유닛 수), Layer =2에서 낸 성능
- $g$의 경우 top candidates로 다음으로 입력된 key
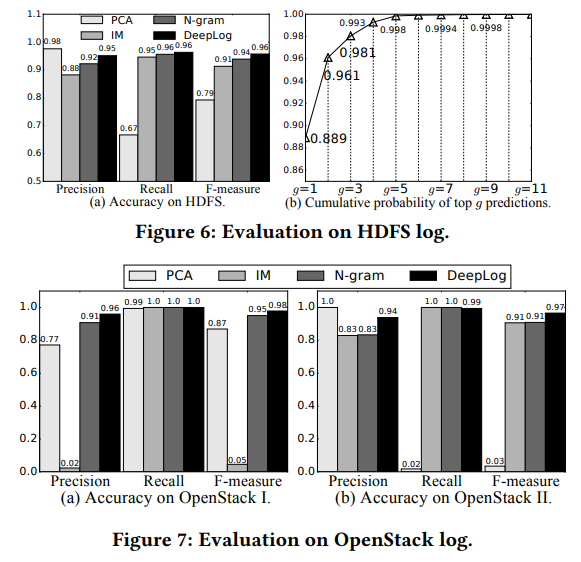
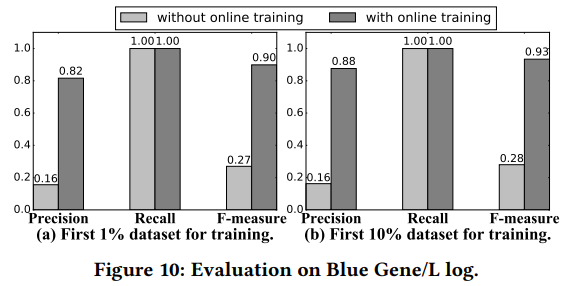
- 실시간 Training이 computing 자원이나 계산 시간을 크게 소모하지 않고 성능을 올릴 수 있음을 경험적으로 제시
- 이미 Deploy된 시스템에 유저 피드백을 통한 weight갱신