Empirical Evaluation of Gated Recurrent Neural Netwoks on Sequence Modeling
Abstract
- 2014년에 발표된 논문으로 GRU를 탄생시킨 조경현 박사님의 후속 연구입니다. 기존 가장 좋은 성능을 내었던 RNN모델인 LSTM과 새로 만든 GRU를 실험적으로 비교합니다
- LSTM vs GRU vs RNNs 비교에서 hidden unit이 있는 LSTM과 GRU이 비슷하면서도 기존 바닐라 RNN방식보다 성능이 좋았습니다
- 하지만 LSTM과 GRU에서 절대적인 우위가 무엇인지는 알 수 없습니다. 다만 task에 따라서 더 성능이 좋은 쪽이 분명 존재하고 또한 learnable parameters의 크기에 제약이 있는지 없는지에 따라서도 한가지 모델을 선택하는 방법이 될 것입니다.
1. Introduction
- 최근 기계번역에서 놀라운 성과들은 LSTM(Hochreiter and Schmidhuber, 1997)과 같은 모델이 주축이 되었다. 이 논문에서는 LSTM과 GRU를 소개하고 tanh RNNs모델과 비교한다.
- 데이터는 다성음악 데이터셋과 스피치 프레젠테이션 데이터셋이 쓰였다.
2. Background : RNN
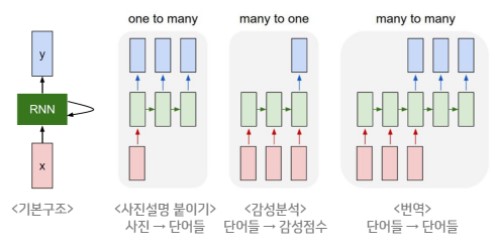
- Recurrent Neural Network라는 이름 그대로 최근의 정보를 신경망의 구조에서 순환시키는 알고리즘. 또한 다양한 길이의 input과 output을 출력한다는 특징이 있습니다
- 기본 수식은 아래와 같다.

- $t=0$에서는 $h_t = 0$이다. 또한 활성함수로 tanh함수를 씀에 주의합니다
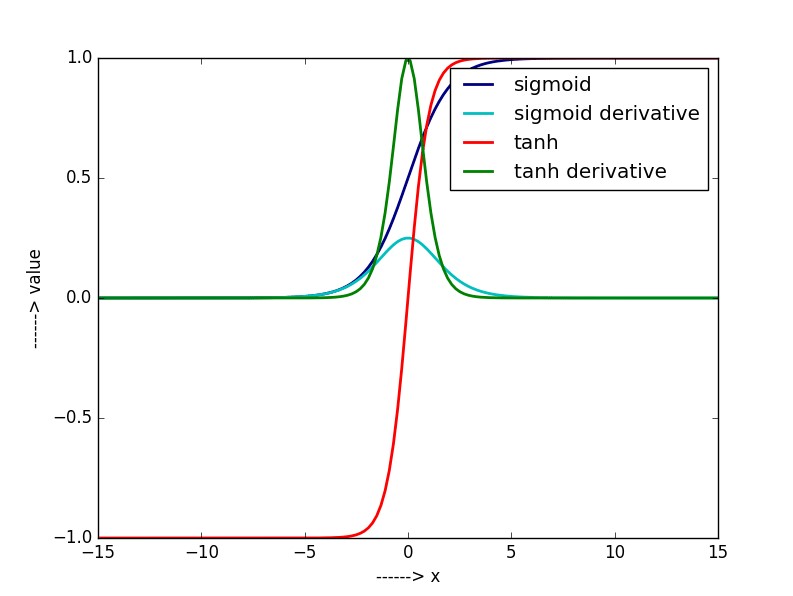
- ❓ $t$ 시점 이전의 입력값의 조건부 확률이 $h_t$라면서 sigmoid말고 왜 tanh을 썻을까요. 찾아보니 오래된 논쟁입니다. sigmoid와 tanh을 미분한 함수를 찾아보면 바로 알 수 있습니다. 기울기의 절대값이 작은 수치를 연속적으로 곱하면 0에 수렴할 가능성이 클테니까요.
- 그럼에도 불구하고 RNN은 기울기 소실로 인한 장기의존성문제(long-term dependencies)가 있음이 밝혀졌습니다. 그동안 크게 두가지 해결책을 고민했습니다. 첫째로, 새로운 optimizer 알고리즘(경사하강법)을 만드는 것입니다. 또 다른 방법으로는 비선형성을 가지도록 돕는 활성함수의 다변화입니다. LSTM은 gating unit이라는 개념을 도입해 마치 새로운 활성함수를 사용한 것 같은 효과를 낸 케이스입니다.
3. Gated RNN
3.1 LSTM
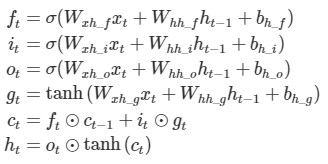
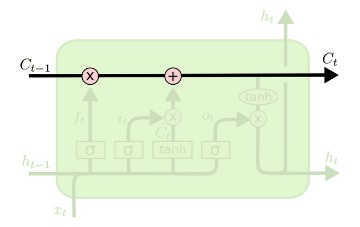
- 핵심 아이디어는 셀 스테이트에서 볼 수 있습니다. 그림에서 볼 수 있듯이 정보가 cell을 통과하며 정보를 계속 전달합니다. $c_t$를 계산하는 과정을 보겠습니다. $c_{t-1}$ 에 $f_t$가 곱해집니다. 이는 얼마나 잊을지 (forget)를 정하고 $i_t$ * $g_t$로 새로운 정보를 얼마나 더해줄지 정합니다.
3.2 GRU
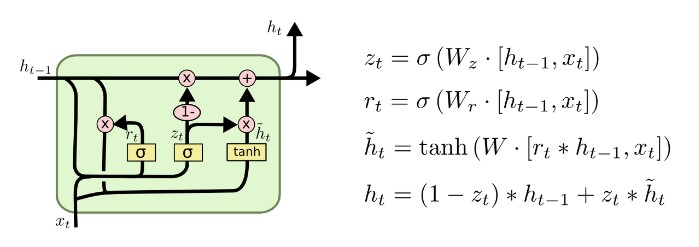
- GRU는 포겟게이트와 아웃풋게이트를 합쳤습니다. 또한 셀 스테이트와 히든 스테이트를 합쳤습니다. 이는 모델이 단순해지는 효과를 불러왔습니다. 여기서 ‘단순함’은 러닝 파라미터의 수가 LSTM에 비해 적어졌다는 것을 의미합니다.
- $r_t$는 리셋게이트로 직전의 정보를 적당히 잊거나 반영합니다
- $z_t$가 forget gate와 input gate를 합친 부분으로 과거정보와 최신정보의 비율을 정해줍니다. $h_t$에서 $(1-z_t)$와 $z_t$가 곱해진 부분을 보면 무슨 뜻인지 단번에 이해가 가능합니다
- 마지막으로 현시점의 정보 후보군을 구합니다. 여기서 중요한 점은(또한 이게 $r_t$랑 다른점은) 후보군을 구할 때 새로운 정보는 그대로 쓰지만 기존 정보는 $r_t$가 곱해진 값을 쓴다는 것입니다.
- 따라서 $h_t$를 구하는 식은 과거후보와 현시점의 후보사이의 비율을 조정하는 식입니다.
4. Experiments Setting
4.1 Tasks and Datasets
$$\max_\theta \frac{1}{N}\sum^N_{n=1} \sum^{T_n}_{t=1}\log p(x^n_t|x^n_1,...,x^n_{t-1};{\theta})$$
- theta가 모델 파라미터일때 log likelihood를 최대화하는 파라미터를 찾는 것이 목표입니다.
- 음악 데이터셋은 각각 93,96,105,108 dim의 이진 벡터이다. output unit에는 sigmoid가 쓰였습니다. 이진벡터이므로 0에서 1사이의 값을 뽑아 목적식을 계산하는 것이 목표라 그런 것으로 추정됩니다.
- 스피치 데이터셋은 처음 20초의 연속된 샘플을 보고 10개의 이후 샘플을 맞추는 task로 설정했습니다.
4.2 Model
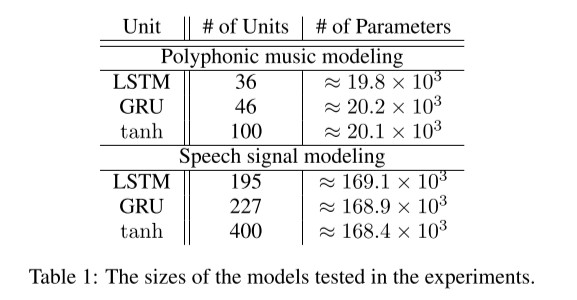
- 파라미터의 수가 최대한 같도록 모델 설계에서 유닛의 수를 조정했다고 합니다
- 이는 최대한 동등한 조건에서 성능을 파악하기 위함이라고 합니다
- train에서 옵티마이저 RMSProp이 사용되었고 웨이트에 sd = 0.075의 노이즈가 추가되었습니다.(Graves, 2011) gradients exploding을 막기위해 gradient의 평균을 1로 표준화했습니다.(Pascanu et al., 2013)
💥
- sd = 0.075를 추가했다는 부분
5. Results and Analysis
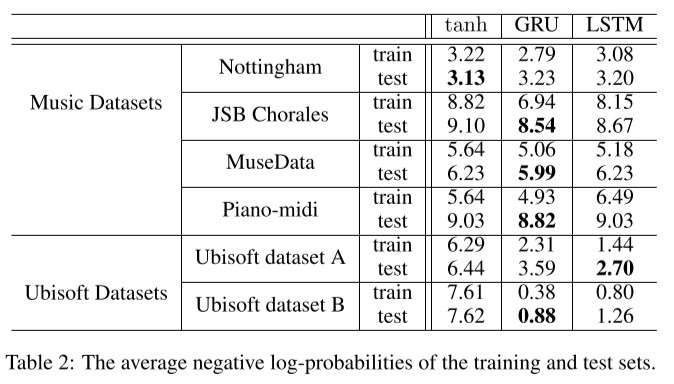
- negative log loss입니다.
- 한가지 경우만 빼면 GRU와 LSTM이 tanh RNNs의 성능을 상회했습니다. 특히 스피치데이터에서는 gate unit이 있는 두 모델이 tanh RNN의 성능을 크게 웃돌았습니다.
- Nottingham Dataset에서는 근소한 차이로 tanh RNN이 좋은 test성능을 내었지만 비슷한 성능을 내는데 필요한 epoch의 수 또는 컴퓨팅 시간(초, second)또한 월등히 많았습니다.
6. Conclusion
we could not make concrete conclusion on which of the two gating units was better
- 지금이야 잘 알려진 사실입니다. 하지만 GRU가 처음 등장할 당시에 유의미한 성능비교를 했다는 것에 논문의 의의가 있습니다. 이 논문의 결과로, 연구자들은 structure나 parameter의 제약을 살피며 LSTM과 GRU 중 알맞는 형태의 RNN모델을 사용할 수 있게 되었습니다.
Reference
https://ratsgo.github.io/natural language processing/2017/03/09/rnnlstm/
https://www.researchgate.net/figure/Sigmoid-tanh-along-with-their-derivatives_fig4_336120224