WaveNet: A Generative Model for Raw Audio
Abstract
- DeepMind에서 2016년에 발표한 음성 출력 모델
- 확률기반 AR모델
1. Introduction
- 뉴럴 네트워크로 이미지를 생산하는 PixelRNN(van den Oord, 2016)으로부터 영감을 얻어 이것을 음성에 적용하고자 했습니다
- 하지만 음성 데이터는 1초에 16,000개의 샘플을 생산합니다. 즉 1초에 처리할 양이 너무 많습니다. 어떻게 문제를 해결했는지는 후에 밝힙니다
- 저자들이 밝힌 contribution은 아래와 같습니다
- 사람이 평가했을 때 자연스러움을 느낀(인위적인 느낌을 받지 못한) 최초의 text-to-speech model
- 음성 데이터가 초당 너무 많은 데이터포인트를 가져 장기의존성 문제를 가지지만, casual conv, dialted conv를 활용해 해결함
- 음악에도 적용 가능함
2. WaveNet
$$p(\mathbf{x})=\prod_{t=1}^{T}p(x_{t}|x_{1},...,x_{t-1})$$
- 각각 모든 오디오 샘플 x_t는 그 전의 timestep들에 대한 조건부 확률로 표현할 수 있습니다.
2.1 Dilated Causal Convolutions
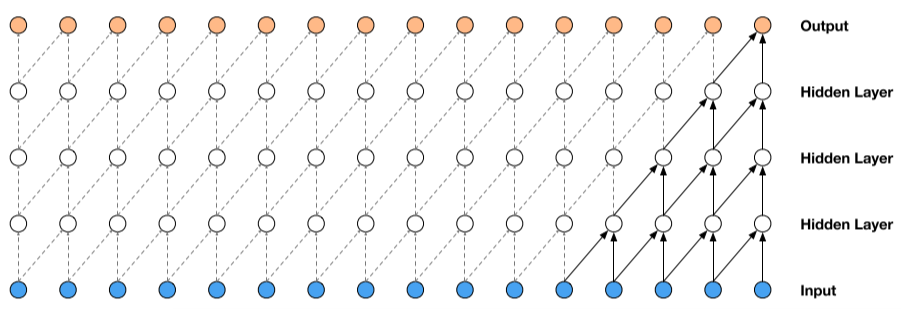
- WaveNet의 철 번 째 핵심은 casual convolution입니다. 여기서 casual이 의미하는 것은 데이터가 시계열성이 존재할 때 이것의 순서를 해치지 않음을 말합니다.
- 위의 그림처럼 5개의 receptive field를 참조하면서 왼쪽에서 오른쪽으로(시간의 순서대로) 연산을 하게됩니다. 마치 CNN에서 마치 필터를 이미지 위에 슬라이싱하듯이 어느 순서대로 연산을 처리하는 것과 비슷하게 보입니다

- 하지만 방금 이미지에서 receptive field가 단 5개 였습니다. 음성은 초당 16,000개의 데이터포인트가 존재할정도로 Dense한 데이터입니다. 기존 방법으로는 이렇게나 많은 데이터를 초 단위로 neural network에 입력시키기 어렵습니다
- padding을 이용하자니 receptive field의 증가라는 측면에서 크게 메리트가 없습니다
- 이것을 dilated convolution이라는 개념을 통해서 해결합니다
- 위의 움직이는 gif이미지를 보면 output 노드 하나는 16개의 receptive filed를 가집니다. output직전의 연산량은 똑같으나 내려다보는 범위가 넓어졌습니다. 이는 dilated conv라는 기법을 사용했기 때문입니다
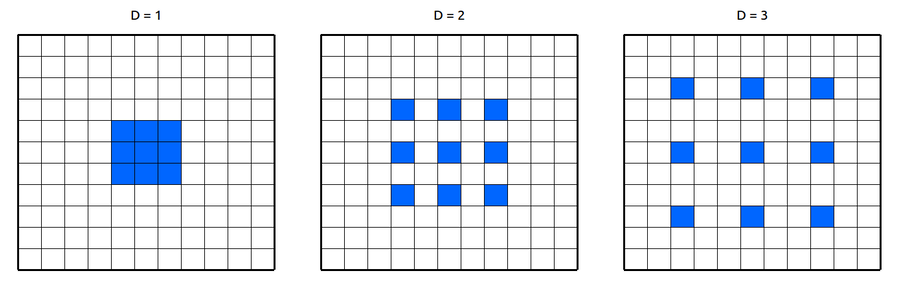
- dilated conv는 이렇듯 연산량 자체를 증가시키지는 않지만 결과적으로 더 넓은 구역의 feature를 뽑을 수 있습니다. 너무 sparse하게 feature를 뽑기때문에 데이터에 적절히 피팅될 수 없다고 생각할 수 있지만 receptive field의 크기가 커야하는 경우에는 잘 작동하는 방식으로 알려져 있습니다.
- WaveNet은 dilated conv의 D가 1에서 10인 것 까지 총 10개의 레이어를 쌓고 다시 이것을 반복하여 총 30개의 레이어를 쌓았습니다. 그러니까 dilated conv레이어만 30개이고 이것의 D는 1,2,4,8….512,1,2,4,…512,1,2…..512 이런식으로 30개 레이어라는 뜻입니다. 이와같은 구조로 WaveNet은 어마어마한 receptive field를 가지게 되었습니다.
- 또한 WaveNet은 예측된 output을 다음 timestep의 input으로 가져옵니다. 이것이 AR모델이라는 설명의 이유입니다
2.2 Softmax Distrubution
- 우선 저자들은 예측값을 “multi class classification”문제로 보았다. 왜일까?
- 16bit의 음성 데이터는 각각 65,536개의 데이터 중 하나의 값을 가진 것들의 연속이다. 즉 모든 데이터가 2^16개의 값 중 하나를 가질 수 있다는 것이다. 그에 반해 8bit 음성 데이터는 2^8 = 256개의 값 중 하나를 가질 수 있을 것이다. 즉 매번 timestep마다 256개의 값 중 어느 값을 가질지 예상하는 것이 task의 목적이라 할 수 있을 것이다.
- 16bit 데이터를 그대로 쓰는 것은 너무나 많은 연산을 여구하므로 256개의 음역으로 quantize화 했다
💥 Quantize화 한다는 것이 무슨 말인가요?
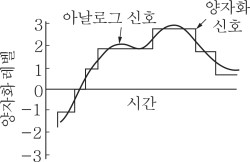
👉🏻자연 아날로그 소리를 근사한 값의 신호로 치환하는 것을 말합니다. 위 task에서는 연속된 아날로그 신호를 256개의 유한한 근사값으로 바꾸어 컴퓨터에 입력하거나 예측하도록 합니다
$$f(x_{t})=sign(x_{t})\frac{ln(1+\mu|x_{t}|)}{ln(1+\mu)}$$
- 여기서 mu = 255 , -1<x_t<1 이라고 논문에 명시되어 있습니다. 논문에수식만 적혀있는 탓에 아날로그 신호를 이렇게 non-linear한 값으로 양자화했다 정도만 알 수 있고 이 식을 어떻게 해석하는지는 알 수 없었습니다. 구글링해봐도 전자공학 전문지식만 단편적으로 나옵니다. 참고로 sign은 부호함수입니다
-
그래서 전파공학 전공하는 친구에게 물어보니 mu는 상수고 x_t는 아날로그 신호가 가지는 진폭이랍니다. 즉 x_t에서 아날로그 신호는 어떤 값을 가질겁니다. 이게 -1보다 작으면 다 -1로 처리하고 1보다 크면 다 1로 처리하겠다는 뜻이랍니다. (여담으로 스마트폰으로 찍은 오케스트라나 합창의 소리가 깨지는 이유가 이와 관련있답니다)
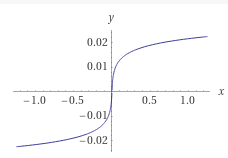
💥연속함수인데 어떻게 discrete한 값으로 표현?
👉plot 해보면 대략 아래와같이 생겼습니다. 치역이 대칭인 기함수입니다. 따라서 y축을 256개의 구간으로 일정하게 나누어서 discrete하게 표현하지 않았을까 생각합니다
2.3 Gated Activation Units
- rectified linear activation function : ReLU
$$\mathbf{z}=tanh(W_{f,k}*\mathbf{x})\odot \sigma (W_{g,k}*\mathbf{x})$$
- WaveNet이 조금 특별한 활성함수(비슷한거,,,)를 썼다는 내용입니다. Odot은 elementwise한 연산을 말하고 f와 g는 필터와 게이트를 뜻합니다. k는 레이어의 index입니다. ReLU보다 성능 좋았답니다.
2.4 Residual and Skip Connections
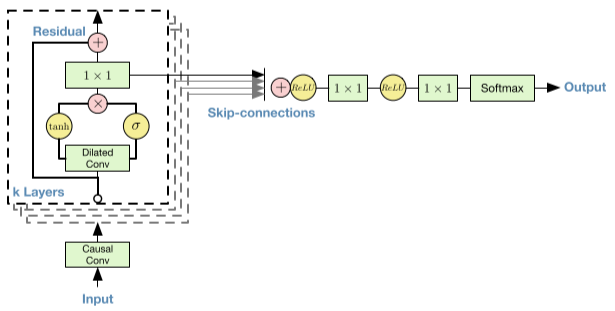
- ResNet이 생각납니다. 수렴속도 향상을 위해서 Residual과 Skip connection을 썼다고 합니다
2.5 Conditional WaveNets
$$p(\mathbf{x}|\mathbf{h})=\prod_{t=1}^{T}p(x_{t}|x_{1},...,x_{t-1},\mathbf{h})$$
- 어떤 새로운 조건 h가 들어왔을 때의 주어진 x에 대한 조건부 확률을 나타냅니다. 예를들어 TTS에서 h는 텍스트정보가 되겠습니다.
- 저자들은 모델은 이렇듯 학습과 다른 인풋h에 대해서 모델이 적응할 수 있도록 하는데 두 가지 방법을 썼다고 합니다.
$$(1)\ \mathbf{z}=tanh(W_{f,k}*\mathbf{x}+V_{f,k}^{T}\mathbf{h})\odot \sigma (W_{f,k}*\mathbf{x}+V_{g,k}^{T}\mathbf{h})$$
$$(2)\ \mathbf{z}=tanh(W_{f,k}*\mathbf{x}+V_{f,k}*\mathbf{y})\odot \sigma (W_{f,k}*\mathbf{x}+V_{g,k}*\mathbf{y})$$
- 앞서 설명한 gated activation unit을 목적에 따라서 (1)또는 (2)로 변경해 사용합니다. (1)은 global한 방법으로 h가 전체에 영향을 미칠 수 있도록 설정되었습니다. (2)은 local한 방법으로 h_t를 또 다른 시계열 자료로 활용하여 매 timestep마다 양자화한 값 y를 대입합니다
- global한 방법은 화자의 정보(목소리 톤), local한 방법은 언어적 특성 이라고 논문에 예시가 있었습니다.
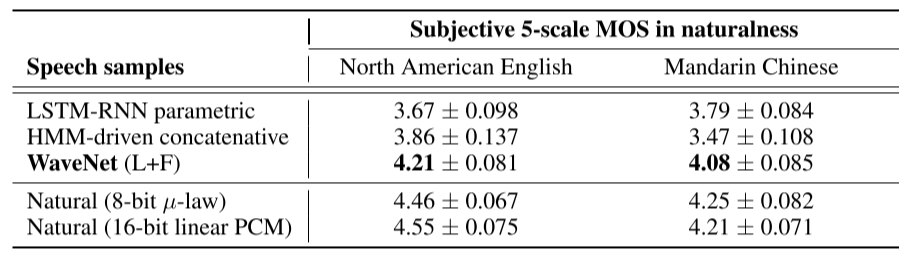
3. Experiments
- Mean opinion score(MOS)
Reference
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio